





Feature Story
More feature stories by year:
2024
2023
2022
2021
2020
2019
2018
2017
2016
2015
2014
2013
2012
2011
2010
2009
2008
2007
2006
2005
2004
2003
2002
2001
2000
1999
1998
 Return to: 2016 Feature Stories
Return to: 2016 Feature Stories
CLIENT: ADESTO
Oct. 18, 2016: Electronic Design
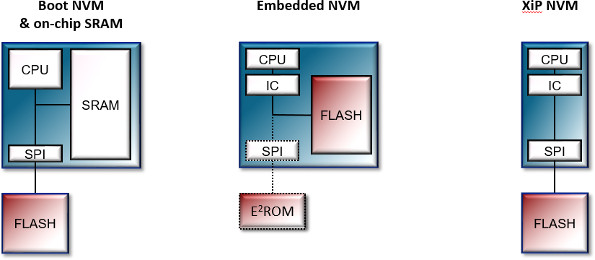
Serial memory provides a low-cost, low-pin-count solution that is ideal for low-cost, low-power mobile applications, such as wearable devices and other connected solutions in the Internet of Things (IoT). Adesto's latest serial memory delivers high performance eXecute-in-Place (XiP) storage for types of applications. The XiP approach can reduce system complexity and cost (Fig. 1).
Of course, there is a trade-off with serial memories: performance. While using fewer signals reduces the throughput, protocol overhead and bus size are also major factors. Simple serial peripheral interface (SPI) devices use a single serial channel. Quad SPI (QPI or QSPI) moves four data bits at a time using seven pins while Octal SPI (OPI) moves eight data bits using only 11 pins. All use significantly fewer pins than a parallel memory interface. There are single (SDR) and double data rate (DDR) implementations that can also affect performance.
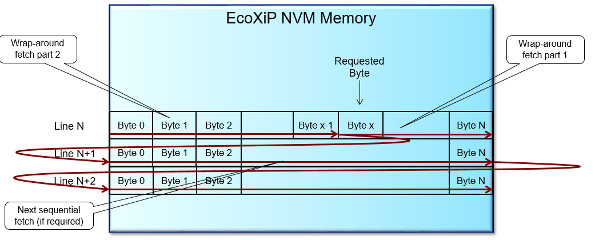
In addition, Adesto has provided a protocol designed to work with processors that have a cache associated with the system. The protocol optimizes the fetching of a 16-byte cache line instead of a single byte (Fig. 2) that is usually delivered in response to a command and an address. This can significantly reduce overhead.
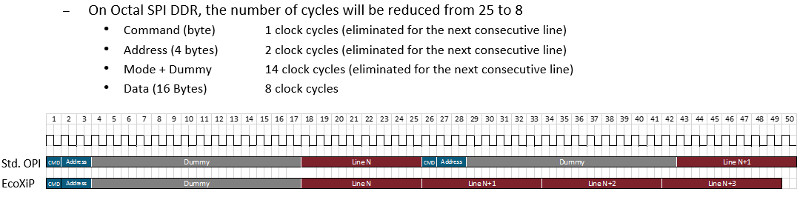
Using only one command and address for one or more cache lines can significantly improve performance (Fig. 3). This provides a 41% speed-up for the processor without changing the clock frequency of the memory. This is a common burst mode technique, with the main difference that the first line of data is ordered based on the initial address.
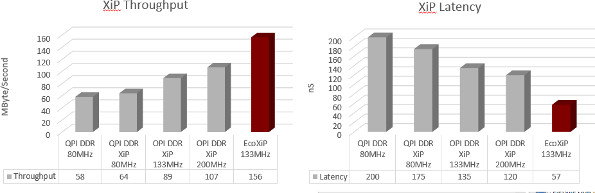
The combination of features allows a 133-MHz device to provide a throughput of 156 Mbyte/s with a latency of only 57ns. This assumes a 16-byte cache line and an average of 3.84 cache line fetches per cache miss. There are versions available that operate at 200 MHz.
Adesto's memory incorporates additional features like a split memory bank. Having two memory partitions allows one to be used for writing while fetching application code from the other. This allows over the air (OTA) updates with a single memory device. Granularity is 1/8th of the memory array. Another feature is auto power down mode and the ability to complete a write while the host is powered down.
Developers can take advantage of the OPI mode alone with many existing chips. Taking advantage of the more advanced support, such as cache line loading, requires compatible processor chips. Adesto is working with microcontroller vendors to make this happen. Ultimately, this could result in substantial power savings and improved system performance.
Return to: 2016 Feature Stories