





Feature Story
More feature stories by year:
2024
2023
2022
2021
2020
2019
2018
2017
2016
2015
2014
2013
2012
2011
2010
2009
2008
2007
2006
2005
2004
2003
2002
2001
2000
1999
1998
 Return to: 2018 Feature Stories
Return to: 2018 Feature Stories
CLIENT: KNOWTHINGS
Aug. 20, 2018: EE Journal
 Realistic Edge-Device Testing
Realistic Edge-Device Testingby Bryon Moyer
We have so many electronic devices in our lives these days. OK, file that under “D” for “Duh!!!,” but how many different kinds do we have? Well… phones, of course. Tablets? Check… Computers? You bet.
After those, things are less obvious. A smart watch? OK… mostly that’s a phone that looks like a watch (and maybe without the phone capabilities, but… who uses a phone as a phone anymore anyway??). But OK… next? (I’m talking regular folks, not buy-all-the-techy-things folks from inside the Silicon Valley bubble…)
Now, if you look into industrial applications, you start to get a lot more. Obviously, folks delivering packages have electronic gadgetry that lets you sign for receipt and lets them keep track of where all those packages go. You see city infrastructure folks with electronic devices that can measure where wires and cables and power are located underground. There are the machines that measure what’s happening within our cars. Etc. etc. etc.
So most of us use one of a dizzying number of available brands of a few kinds of items. Industry uses many more specialized, purpose-built devices. The question is, how do you test to be sure that all of these things communicate correctly and with the desired performance?
For us consumers, it’s not so hard (tell that to the testing guy though…). You’ve got a very few protocols to worry about carrying generic data from things like browsers, apps, and phone calls. So you can test the bejeebus out of them. How do you model the traffic? Well, since there are only a few classes of platform, you can expend the effort to build a purpose-built data generator for use in testing – that is, if you can’t simply plug into a real data source coming out of the wall or the air.
What about those more specific industrial devices? Well, there you have a moderate number and a limited audience; you can probably also model that traffic pretty clearly.
So here we have either wide scope with a limited number of platforms or narrow scope and a greater number of platforms (although probably not a crazy number). What’s going to happen if the Internet of Things (IoT) explodes for consumers the way it’s been predicted? Or even for industry? Now we’ll have a wide scope and a huge number of purpose-built widgets, each of which is likely to have some level of proprietary behavior even if it uses industry-standard protocols for most network layers.
The challenge here is primarily scaling and stress: you can test a single unit and have it work just fine, but what if that single unit suddenly becomes a thousand or a million or more? Can the infrastructure handle the load with the required performance?
With network layers below the application layer, performance may be governed by well-known protocols. But at the app layer, the data patterns will be specific to that applications. Yes, on a phone, an “app” is but one program on a generic computing platform. But with the IoT, an app is an entire device with a dedicated purpose. Does every device maker have to spend the time and effort to design and validate testing models for each unit they design?
What’s more likely is that you build a few prototype units and test them. All well and good, but how do you test the device’s ability to scale? You don’t want to have to built thousands of prototypes for stress testing.
Or perhaps you’re adapting existing industrial equipment for the IoT – a so-called brownfield installation. Now thousands of devices exist, but they’re already installed at sites around the world. Do you have to buy a couple thousand to run the stress tests?
Traditionally, you would now be consigned to the woodshed to spend valuable time developing bespoke data generators rather than working on the next product that you can sell. But, instead of doing that, might you be able to summon up the Thing That Will Save Everything? Machine learning?
Stressing Out
KnowThings thinks that you can. They’ve got a system for generating models automatically, using AI to build the model.
There are two pieces to the models they can help you to simulate:
AI’s role is to listen to data from a device. The model generator will identify the patterns in the data through a variety of usage scenarios, categorizing the various packets with machine-generated tags. You can then go in and edit those tags to make them more human-digestible.
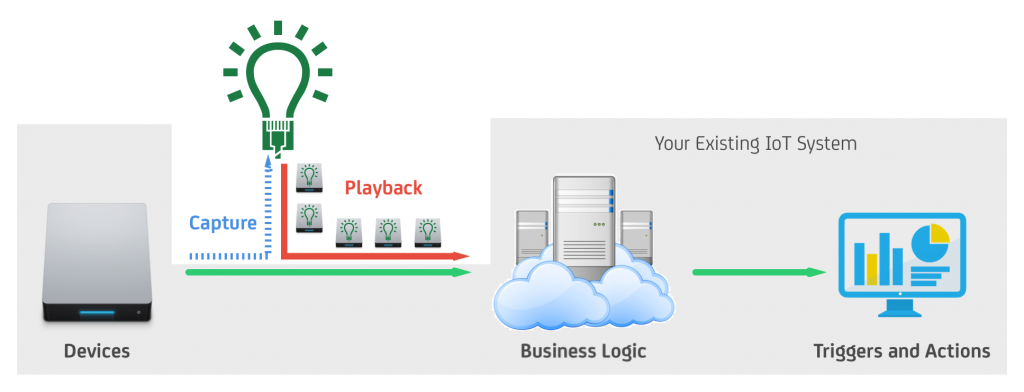
(Image courtesy KnowThings)
But what if you don’t have a device yet? They’re also working on a manual modeling capability using a simple language to describe the model. Initially, components included in the model will be generic – that is, they won’t reflect the detailed behavior of one brand of device vs. another. But their vision includes getting to that level of detail, meaning that you could do, for example, second-source evaluations.
So now you have two capabilities: manual, for when you don’t have built hardware yet, and automatic, for when you do. The third capability manages the transition: letting the manual model inform and provide semantic clues to the Ai process as you go from a virtual unit to a real unit.
What you get with these models is the ability to push your devices and system to see where (or if) they break. But let’s say that you have a model with human-understandable tags so that you can go in and inspect the results of a data capture. What happens if some unknown or, even worse, unauthorized traffic comes through?
Unexpected or novel data patterns will still be characterized; they just won’t have a nice, easy-to-read tag for what they represent. They’ll be mystery patterns. You can then go figure out whether they represent some mode or use case that you hadn’t run across yet. If not, then it may indicate a security issue – someone injecting malicious traffic into your stream.
So if this pans out as promised, you may have an easier way to test your edge devices. Of, if the effort has had you skimping on the testing, you can skimp no more.
Return to: 2018 Feature Stories