





Feature Story
More feature stories by year:
2024
2023
2022
2021
2020
2019
2018
2017
2016
2015
2014
2013
2012
2011
2010
2009
2008
2007
2006
2005
2004
2003
2002
2001
2000
1999
1998
Return to: 2012 Feature Stories
CLIENT: IMAGINATION TECHNOLOGIES![]()
Aug. 23, 2012: Computing Now
The current trend of using cores aimed at rendering graphics to perform computational tasks usually handled by the central processing unit has had a major impact on the way programmers develop their applications.
The concept implies using graphic processing units (GPUs) and CPUs together in modern system on a chip (SoCs) with the sequential part of the application running on the CPU while the data-parallel, computational-intensive side, which is often more substantial, is handled by the GPU. The momentum for embracing the GPU compute model has been rapidly picking up as some experts have predicted that it is likely to increase its current capabilities by 500x, while "pure" CPU capacities will progress by a limited 10x.
This enables graphics processors to achieve tremendous computational performance and maintain power efficiency while at the same time offering the end user an incredible overall system speedup that is transparent, seamless, and easy to achieve.
Able to access the hardware solutions but lacking the software support, applications initially attempted to match the feature set of traditional graphics application programming interfaces (APIs) like OpenGL. This proved to be somewhat inefficient and thus a number of solutions have started to appear for the GPU compute programming problem.
Developments in dedicated multi-threaded languages such as OpenCL (driven by Apple at first, but now a widely adopted Khronos standard), DirectX 11.1 (enabling access to the DirectCompute technology), and C for Compute Unified Device Architecture (CUDA) have been driven by key semiconductor and software companies to become a tangible reality. In the high-performance workstation market, there are FireStream and CUDA-compliant products, although neither of those standards has been ported to the embedded space.
The success of this approach was such that the industry started looking at floating point operations per second (Flops) instead of CPU frequency, when comparing a computing system's overall speed. From the graph below, we can see most GPUs have started to outclass high-end mobile CPUs by a large margin when looking at computational capacity.
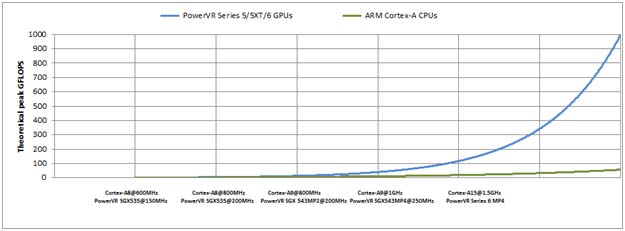
The theoretical performance of GPUs vs. CPUs.
Firstly, if we look under the hood of the two most important processors in a typical SoC, CPUs and GPUs have a slightly different structure and functionality. CPUs generally have really fast cache memories, which makes them suitable for data reuse scenarios. Coupled with fine branching granularity and the ability to achieve high performance on a single thread of execution, they are good for task parallelism but traditionally suffer from high overall system latency.
There have been some solutions to address these problems by using a combination of multicore configurations or enabling multi-threaded functionality but these have had a limited impact, especially in mobile. GPUs, on the other hand, employ a large number of mathematical units called arithmetic logic units (ALUs), have fast access to system memory and are able to run a dedicated program on each vertex or pixel (these are known as shaders). Because they offer high throughput on parallel tasks, they are particularly good in data parallelism scenarios, where the programmer usually has to execute the same computation on a large set of data and no dependencies exist between elements in each step of the algorithm.
Therefore, the notion that GPU compute will magically replace CPUs has been promoted by some as the way forward, hence the general purpose GPU (GPGPU) moniker. But this is a somewhat distorted view of what a graphics core can offer you, as in the embedded and mobile space there is a particular set of ideal apps where GPU compute can make a significant difference. If you have a large data set, high arithmetic intensity, and parallelism then this technology can be the solution for you. For example, Phil Colella first popularized the term "The Seven Dwarfs" to describe key algorithmic kernels that can benefit from GPU compute in 2004. This was later expanded to 13 by a group of researchers at University of California, Berkeley, in 2006.
The initial scientific-oriented applications were categorized as follows:
From the excellent progress which has been made in some of these fields, real applications have started to benefit from the parallelism encountered in Fast-Fourier transform (FFT) libraries or turbulent fluid flow application frameworks and now smartphones can include useful features like voice search or face unlock using GPU acceleration.
Imagination's PowerVR graphics technologies support all the main APIs now in use for GPU computing, which are presently getting wider deployment, particularly in desktop products, but also in embedded systems.
Implementing advanced capabilities such as round-to-nearest in floating-point mathematics, full 32-bit integer support and 64-bit integer emulation, Imagination was able to become an early adopter of OpenCL. These features that enable GPU computing have been already integrated in several popular platforms that can be found in most of the mobile phones and tablets. By offering the possibility to combine up to 16 PowerVR SGX cores on a chip, Imagination is able to deliver performance on par with discrete GPU vendors, while still retaining an unrivalled power, area, and bandwidth efficiency.
Because power consumption increases super-linearly with frequency, the PowerVR SGX family achieves high parallelism at low clock frequencies, therefore enabling programmers to write efficient applications that can benefit from the OpenCL mobile API ecosystem. This enables advanced applications and parallel computing for imaging and graphics solutions.
The newly launched PowerVR Series 6 IP cores address the problem of achieving optimal general-purpose computational throughput while taking into account memory latency and power efficiency. This revolutionary family of GPUs is designed to integrate the graphics and compute functionalities together, optimizing interoperation between the two, both at hardware and software driver levels.
It has been designed with GPU compute in mind, supporting all major industry standards including: OpenCL, Renderscript Compute, and DirectCompute (whereas some suppliers have decided to either go with a limited set or just ignore some of them altogether). By introducing a cluster-based architecture, PowerVR has evolved into a scalable platform that can be optimized for best results in performance, power, and area without sacrificing anything in terms of features.
There is an ever-expanding variety of use cases where GPU computing based on PowerVR graphics cores brings great benefits. Examples include:
Another very important aspect of Power VR Series 6's GPU compute capabilities lies in how the graphics core can dramatically improve the overall system performance by offloading the CPU. The new family of GPUs offers a multi-tasking, multi-threaded engine with maximal utilization via a scalar/wide SIMD execution model for maximal compute efficiency and ensures true scalability in performance, as the industry is sending a clear message that the CPU-GPU relationship is no longer based on a master-slave modelodel but on a peer-to-peer communication mechanism.
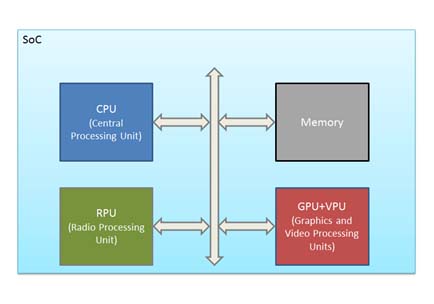
With its design targeting efficiency in the mobile space, the CPU is fundamentally a sequential processor. Therefore, it cannot handle intensive data-plane processing without quickly becoming overloaded and virtually stalling the whole system. As a result, computing architectures need to become heterogeneous systems, with true parallel-core GPUs, like the PowerVR Series 6 IP graphics cores, working together with multicore CPUs and other processing units within the system.
Concepts like GPU computing and heterogeneous processing architectures are not new, as most systems nowadays can be already considered heterogeneous. Just by looking at any smartphone or tablet, one can see this approach in SoC integration for the mobile market. Even personal computers have been integrating the CPU and GPU more closely on the same chip.
The new trend has now shifted towards integrating several different types of programmable processors onto the same chip, like video processing units (VPUs) and remote processing units (RPUs), with users having to take full advantage of this type of approach to get the most out of their system. For those with a strong graphics background, this might seem like an easy task as they are used to do all the hard work behind writing kernels using variants of high level languages or even directly, through assembly.
But in order for GPU compute and heterogeneous processing, in general, to succeed there needs to be an easier way to do this. Therefore, organizations like the Khronos group or the HSA Foundation, of which Imagination is a founding member, are working to deliver the required framework, including standardized ISAs, programming guides, and language abstraction, which will lead to an increase in the number of applications taking advantage of these new technologies.
Also, as academic research is still one of the strongest driving forces behind this, innovation in universities will bring interesting new twists and solutions to take GPU compute to the mainstream. Vendors and members of the community will need to work together to make tomorrow's platforms more efficient and software has to be designed for scalability on future systems.
Thanks to new developments in mobile architectures, gigaflops for GPUs has become a reality faster than anyone had predicted and speed-ups with factors of 10x or 20x are now the norm, so it is now crucial that any developer must be aware of this and take advantage of these new possibilities.
Return to: 2012 Feature Stories